Microservice & Domain Driven Design
Define Domain Boundary for Microservice
Identifying domain model boundaries for each microservice is
a crucial step in designing a microservices architecture. It helps in
organizing the system into distinct services that are modular, scalable, and
maintainable. Here are general steps and considerations for identifying these
boundaries:
1. Understand the Business Domain
- Domain
Analysis: Start by understanding the business domain. Identify the key
entities, their relationships, and the business processes that involve
these entities. This understanding will guide the segregation of services.
- Business
Capabilities: List down the core capabilities your application needs
to provide. These capabilities often hint at potential service boundaries.
2. Domain-Driven Design (DDD)
- Bounded
Contexts: Use Domain-Driven Design principles to define bounded
contexts. A bounded context is a specific responsibility or function
within the domain that has a clear boundary. Each microservice should
align with one bounded context.
- Aggregates:
Within each bounded context, identify aggregates. An aggregate is a
cluster of domain objects that can be treated as a single unit. An
aggregate root is the entity within the aggregate that is the entry point
from an external query perspective.
3. Service Granularity
- Size
and Scope: Determine the size and scope of each service. A
microservice should be small enough to be managed by a small team but
large enough to provide a meaningful business capability.
- Decomposition
by Subdomain: Decompose the system by subdomains (sub-parts of your
business domain) that are closely aligned with DDD's bounded contexts.
4. Identify Integration Points
- APIs
and Events: Identify how services will communicate with each other.
This could be through RESTful APIs, event streams, or message queues. The
integration points should respect the autonomy of each service.
- Data
Duplication: Accept some level of data duplication across services to
ensure they remain decoupled.
5. Continuous Refinement
- Iterative
Approach: Domain boundaries may evolve as the understanding of the
domain improves or as the business requirements change. Be prepared to
refine service boundaries over time.
- Feedback
Loop: Use feedback from development, deployment, and operation to
reassess and refine the boundaries.
Practical Steps
- Conduct
Workshops: Organize workshops with stakeholders and domain experts to
map out the domain model and identify bounded contexts.
- Modeling
Techniques: Use techniques like Event Storming or User Story Mapping
to visualize and identify domain events and user interactions that can
influence service boundaries.
- Prototype
and Experiment: Build prototypes to validate your understanding of the
domain and the feasibility of your proposed service boundaries.
- Documentation:
Document the responsibilities, interfaces, and data schema of each
microservice. This documentation should be maintained and updated as the
system evolves.
Example
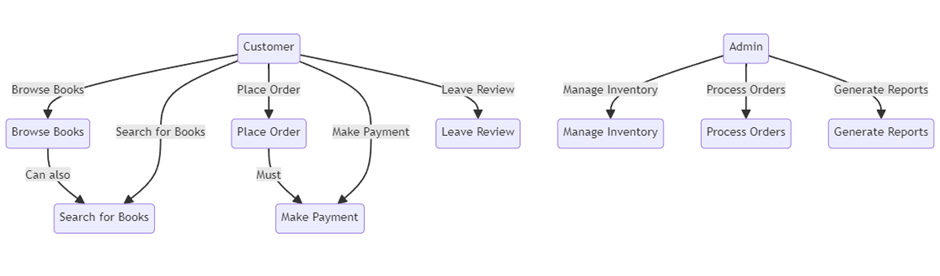
Figure 1 Use Cases for the online bookstore.
Imagine you are building an e-commerce platform. You might
identify the following bounded contexts as potential
microservices:
- Catalog
Service: Manages product listings, categories, and inventory.
- Ordering
Service: Handles shopping cart management, order placement, and order
fulfillment.
- Payment
Service: Processes payments, refunds, and financial records.
- Customer
Service: Manages customer profiles, authentication, and authorization.
In summary, identifying domain model boundaries for
microservices involves a deep understanding of the business domain, using
principles of Domain-Driven Design to define bounded contexts and aggregates,
considering service granularity, identifying integration points, and
continuously refining the model based on feedback and evolving requirements.
Domain Driven Design
Domain-Driven Design (DDD) is a software design approach
that focuses on modeling software to match the domain it aims to serve. It
emphasizes collaboration between technical experts and domain experts to create
a model that reflects the domain's complexities and nuances. Here's a
simplified example illustrating how DDD can be applied to develop a software
solution, using an online bookstore as the domain.
Domain: Online Bookstore
Step 1: Identify the Domain and Subdomains
- Core
Domain: Book sales, which is the primary business capability and
includes managing inventory, sales, and customer interactions.
- Supporting
Subdomains: Recommendations (suggesting books based on customer
behavior), Ratings & Reviews.
- Generic
Subdomains: Payment processing, Shipping.
Step 2: Engage Domain Experts
Work closely with domain experts (e.g., bookstore managers,
sales personnel) to gain insights into the domain, understand business
processes, challenges, and terminology.
Step 3: Model the Domain (Strategic Design)
- Bounded
Contexts: Define clear boundaries around distinct models within the
domain. For the online bookstore, possible bounded contexts might include:
- Inventory
Management
- Sales
& Orders
- Customer
Management
- Recommendations
- Payments
- Shipping
Step 4: Define Ubiquitous Language
Develop a common language based on the domain model that is
shared between developers, domain experts, and stakeholders. For instance:
- Book:
An entity representing a book, including metadata like ISBN, title,
author, price, and stock level.
- Order:
A customer's request to purchase one or more books, including details like
order ID, customer ID, order items, total price, and status.
- Cart:
A collection of items that a customer intends to purchase.
Step 5: Implement Using Building Blocks (Tactical Design)
- Entities:
Objects that are defined by their identity, such as a Book or a Customer.
- Value
Objects: Objects that describe characteristics of things, like a
Book's Price or a Customer's Address, without needing a unique identity.
- Aggregates:
A cluster of associated objects treated as a single unit, like an Order
aggregate that includes Order Items and can perform operations like adding
an item or calculating the total.
- Repositories:
Mechanisms for storing and retrieving aggregates, such as a BookRepository
or an OrderRepository.
- Services:
Define operations that don't naturally fit within an entity or value
object, such as a RecommendationService that suggests books based on
customer preferences.
- Domain
Events: Recognize significant business activities that trigger side
effects, like an OrderPlaced event, which might trigger processes in
shipping and inventory management.
Step 6: Continuous Integration
- Keep
the model and its implementation aligned with ongoing insights from the
domain through continuous integration of the code, model, and domain
knowledge.
Example in Practice
Imagine implementing the Sales & Orders bounded context.
The domain model might include entities such as Order and OrderItem
(aggregates), with value objects like OrderStatus and Money. The
ubiquitous language around these concepts ensures all team members and domain
experts have a shared understanding of their meaning and use within the system.
This approach helps in creating a modular, flexible
architecture where the software closely mirrors the domain complexities,
enabling easier maintenance, scalability, and alignment with business goals.
Document Layout
Creating effective documentation for a Domain-Driven Design
(DDD) project involves detailing the strategic and tactical design decisions,
the domain model, and how the system's architecture supports the domain's
complexities. Here's a sample layout for DDD documentation that can help ensure
clarity, maintainability, and ease of onboarding for new team members.
1. Overview
- Project
Introduction: A brief description of the project, its goals, and the
domain problem it aims to solve.
- Key
Objectives: The core objectives and expected outcomes of the project.
2. Domain Overview
- Domain
Description: An overview of the domain, including its significance and
key challenges.
- Domain
Glossary: A glossary of ubiquitous language terms and their
definitions used across the domain.
3. Strategic Design
- Core
Domain: Explanation of the core domain and its criticality to the
business strategy.
- Subdomains:
- Core
Subdomains: Detailed descriptions of each core subdomain.
- Supporting
Subdomains: Overview and roles of supporting subdomains.
- Generic
Subdomains: Identification of generic subdomains and standard
solutions applied.
- Context
Mapping: Diagrams and explanations of bounded contexts, including
their relationships (e.g., partnerships, shared kernels,
customer/supplier, anticorruption layers).
4. Bounded Contexts
For each bounded context:
- Name
and Description: What it represents and its domain logic.
- Responsibilities:
Key responsibilities and its domain significance.
- Models
and Entities: Description of entities, value objects, aggregates,
services, and domain events.
- Context
Interfaces: Public APIs, events, and services provided to other
contexts.
- Data
Model: Entity-Relationship diagrams or other relevant data models.
- Integration
Points: How it integrates with other bounded contexts, including
upstream and downstream dependencies.
5. Tactical Design
- Aggregates:
Definitions, boundaries, and root entities.
- Domain
Services: Services implementing domain logic that doesn't naturally
fit into entities or value objects.
- Repositories:
Persistence mechanisms for aggregates.
- Factories:
How complex objects and aggregates are created.
- Domain
Events: Events that signify important domain changes or activities.
6. Architecture
- Overview:
High-level architecture showing how bounded contexts are implemented
(microservices, modules, etc.).
- Infrastructure
Design: Key infrastructure components supporting the system
(databases, messaging systems, etc.).
- Security
Model: Security measures and protocols in place to protect the domain
and its data.
7. Implementation Details
- Technology
Stack: Technologies used for implementing the system.
- Code
Structure: Overview of the codebase organization, including key
modules and their purposes.
- Development
Practices: Key development practices, standards, and conventions
adopted by the team.
8. Deployment and Operations
- Deployment
Architecture: Overview of the deployment infrastructure.
- CI/CD
Pipelines: Continuous integration and delivery processes.
- Monitoring
and Logging: Strategies for monitoring system health and logging
important events.
9. Guides and Examples
- Usage
Examples: Code snippets or API examples demonstrating how to work with
core domain models or services.
- Patterns
and Practices: Best practices and patterns used in the project (e.g.,
Event Sourcing, CQRS).
10. Change Log
- Version
History: Document major changes, decisions, and their rationale over
time.
Appendix
- Additional
Resources: Links to external resources, further readings, and domain
research materials.
- Contributors:
List of contributors and their roles in the project.
This layout can be adapted based on project size,
complexity, and specific needs. The key is to ensure that the documentation
effectively communicates the domain model, design decisions, and how the
system's design addresses the domain's challenges.
Service Granularity
Service granularity in a microservices architecture refers
to how much responsibility and functionality a single service encompasses. It's
a balance between having too many small, overly specialized services (leading
to complex orchestration and communication overhead) and having too few large,
monolithic services (leading to challenges in scaling, maintaining, and
updating parts of the system independently). Using the online bookstore
example, I'll illustrate how service granularity can be effectively managed.
Example of Service Granularity in Online Bookstore
1. Catalog Service (Medium Granularity)
- Responsibilities:
Manages the book inventory, including details like titles, authors, ISBNs,
prices, and stock levels. It also provides search functionality to find
books based on various criteria.
- Justification:
Combining inventory management with search functionality strikes a balance
between granularity and practicality. It avoids the overhead of separate
services for managing book details and searching, which would tightly
couple these functions anyway due to their close relationship.
2. Sales & Orders Service (Medium Granularity)
- Responsibilities:
Handles the creation and management of customer orders, from cart
management to order placement. This service is responsible for calculating
the total cost, applying discounts, and managing the state of an order
(e.g., pending, completed, canceled).
- Justification:
Keeping cart management and order processing in a single service
simplifies the transactional aspects of managing orders, such as ensuring
inventory is reserved and then decremented upon order completion.
Splitting these could introduce unnecessary complexity in coordinating
transactions across services.
3. Payment Service (Fine Granularity)
- Responsibilities:
Processes payments for orders. It handles different payment methods
(credit cards, PayPal, etc.), interfaces with payment gateways, and
manages payment confirmations and receipts.
- Justification:
A fine-grained service for payments allows for focused scaling and
updates, given the sensitivity and fluctuating demands of payment
processing. It also facilitates compliance with financial regulations and
easier integration with various payment gateways.
4. Shipping Service (Fine Granularity)
- Responsibilities:
Manages the shipment of books once an order is completed. It includes
generating shipping labels, tracking shipment status, and handling
returns.
- Justification:
Separating shipping into its own service allows for independent scaling
and updates, which is crucial for adapting to changes in shipping
logistics, integrating with multiple couriers, and handling complex
shipping rules.
5. User Account and Profile Service (Medium Granularity)
- Responsibilities:
Manages user registration, authentication, and profile management,
including storing user preferences and browsing history.
- Justification:
Consolidating user-related functionalities facilitates a centralized
approach to user management, security, and personalization. It avoids
scattering user information across services, which would complicate data
management and privacy compliance.
6. Recommendation Service (Fine Granularity)
- Responsibilities:
Provides personalized book recommendations to users based on their
browsing history, purchase history, and preferences.
- Justification:
A specialized service for recommendations allows for the use of
sophisticated machine learning models and algorithms that can be
independently developed, deployed, and scaled without impacting other
bookstore functionalities.
Considerations for Determining Service Granularity:
- Domain
Complexity: More complex domains may require finer granularity to
manage complexity effectively.
- Scalability
Needs: Services that handle high loads may benefit from being
separated to scale independently.
- Development
and Deployment: Finer granularity can lead to more flexible
development and deployment cycles for specific functionalities.
- Data
Management: Consider how data is shared and managed across services to
avoid tight coupling and ensure consistency.
This example demonstrates a balanced approach to service
granularity in the context of an online bookstore, aiming to optimize for
maintainability, scalability, and development efficiency.
Identify Integration Points

Figure 2 Identify integration points via a system diagram.
Integration points in a microservices architecture refer to
the specific ways in which different services communicate and interact with
each other to perform their functions. These points are crucial for the overall
system's functionality, consistency, and reliability. Using the online
bookstore example, let's identify potential integration points among the
services we've discussed.
Example Integration Points in Online Bookstore
1. Catalog Service to Sales & Orders Service
- Integration
Point: When a customer places an order, the Sales & Orders Service
needs to check the availability of the requested books with the Catalog
Service.
- Method:
RESTful API call from Sales & Orders Service to Catalog Service to
retrieve book availability and details.
- Data
Shared: Book IDs and quantities.
- Purpose:
Ensures that orders are only placed for books that are available in the
inventory.
2. Sales & Orders Service to Payment Service
- Integration
Point: Once an order is confirmed and needs to be paid, the Sales
& Orders Service sends the payment details to the Payment Service.
- Method:
Secure API call to initiate payment processing.
- Data
Shared: Order ID, payment amount, and payment method details.
- Purpose:
Processes the payment for an order and updates the order status upon
successful payment.
3. Payment Service to Sales & Orders Service
- Integration
Point: After a payment is processed, the Payment Service notifies the
Sales & Orders Service of the payment result (success or failure).
- Method:
Webhook or event message through a message broker.
- Data
Shared: Order ID, payment status, transaction ID.
- Purpose:
Updates the order status based on the payment result and triggers further
order processing steps.
4. Sales & Orders Service to Shipping Service
- Integration
Point: For each completed and paid order, the Sales & Orders
Service requests the Shipping Service to handle the shipment.
- Method:
Messaging queue or direct API call to create a shipping request.
- Data
Shared: Order ID, customer address, list of books to ship.
- Purpose:
Initiates the shipping process for fulfilled orders and enables shipment
tracking.
5. User Account and Profile Service to Recommendation
Service
- Integration
Point: The Recommendation Service fetches user activity and
preferences from the User Account and Profile Service to generate
personalized book recommendations.
- Method:
API call to retrieve user browsing and purchase history.
- Data
Shared: User ID, browsing history, purchase history.
- Purpose:
Allows the Recommendation Service to tailor book suggestions based on
individual user preferences and activities.
6. Catalog Service to Recommendation Service
- Integration
Point: The Recommendation Service accesses the Catalog Service to
fetch details about books to include in recommendations.
- Method:
RESTful API call to retrieve book details.
- Data
Shared: Book IDs.
- Purpose:
Ensures that the recommendations include relevant and up-to-date
information about books, such as titles, authors, and covers.
Considerations for Effective Integration
- Loose
Coupling: Services should be designed to minimize dependencies on each
other, allowing for changes in one service without significantly impacting
others.
- Data
Consistency: Use transactional outbox patterns, event sourcing, or
distributed transactions (where necessary) to maintain data consistency
across services.
- Scalability
and Performance: Design integration points to support scaling,
considering asynchronous communication (e.g., event-driven) where
appropriate to improve performance.
- Security:
Secure all integration points using authentication, authorization, and
encryption to protect sensitive data.
These examples of integration points illustrate how different services within the online bookstore interact to provide a seamless and efficient user experience while maintaining the system's integrity and performance.
Comments
Post a Comment